 Krátké bajty: Webový prohledávač je program, který prochází internet (World Wide Web) předem určeným, konfigurovatelným a automatizovaným způsobem a provádí danou akci s procházeným obsahem. Vyhledávače jako Google a Yahoo používají spidering jako prostředek k poskytování aktuálních dat.
Krátké bajty: Webový prohledávač je program, který prochází internet (World Wide Web) předem určeným, konfigurovatelným a automatizovaným způsobem a provádí danou akci s procházeným obsahem. Vyhledávače jako Google a Yahoo používají spidering jako prostředek k poskytování aktuálních dat.
Společnost Webhose.io, která poskytuje přímý přístup k živým datům ze stovek tisíc fór, zpráv a blogů, zveřejnila 12. srpna 2015 články popisující malý webový prohledávač s více vlákny napsaný v pythonu. Tento webový prohledávač python je schopen procházet celý web za vás. Ran Geva, autor tohoto malého pythonového webového prohledávače, říká, že:
Psal jsem jako „Dirty“, „Iffy“, „Bad“, „Not very good“. Říkám, že to zvládne a stáhne tisíce stránek z více stránek během několika hodin. Není vyžadováno žádné nastavení, žádné externí importy, stačí spustit následující kód pythonu se semenným webem a sedět (nebo jít udělat něco jiného, protože to může trvat několik hodin nebo dní v závislosti na tom, kolik dat potřebujete).Vícevláknový prohledávač založený na pythonu je velmi jednoduchý a velmi rychlý. Je schopen detekovat a eliminovat duplicitní odkazy a uložit zdroj i odkaz, které lze později použít při hledání příchozích a odchozích odkazů pro výpočet hodnocení stránky. Je zcela zdarma a kód je uveden níže:
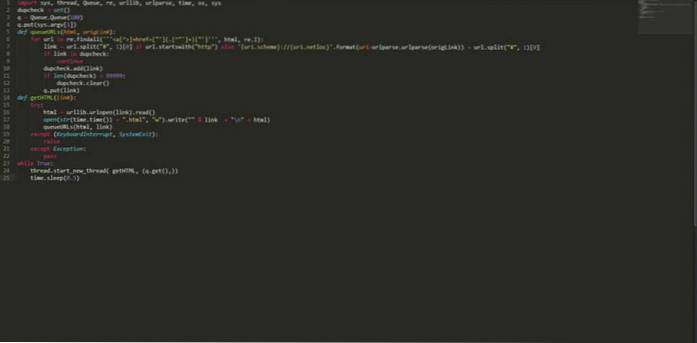
import sys, thread, Queue, re, urllib, urlparse, time, os, sys dupcheck = set () q = Queue.Queue (100) q.put (sys.argv [1]) def queueURLs (html, origLink): pro adresu URL v re.findall ("] + href = ["'] (. [^"'] +) ["']", html, re.I): link = url.split ("#", 1) [0] pokud url.startswith ( "http") else 'uri.scheme: // uri.netloc' .format (uri = urlparse.urlparse (origLink)) + url.split ("#", 1) [0] pokud je odkaz v dupchecku : continue dupcheck.add (link) if len (dupcheck)> 99999: dupcheck.clear () q.put (link) def getHTML (link): try: html = urllib.urlopen (link) .read () open (str (time.time ()) + ".html", "w"). write (""% link + "\ n" + html) queueURLs (html, link) kromě (KeyboardInterrupt, SystemExit): zvýšit kromě Výjimka: předat while True: thread.start_new_thread (getHTML, (q.get (),)) time.sleep (0.5) Uložte výše uvedený kód s nějakým názvem, řekněme „myPythonCrawler.py“. Chcete-li začít procházet jakýkoli web, zadejte:
$ python myPythonCrawler.py https://fossbytes.com
Pohodlně se usaďte a užívejte si tento webový prohledávač v pythonu. Stáhne vám celý web.
Staňte se profesionálem v Pythonu s těmito kurzy
Líbí se vám tento mrtvý jednoduchý vícevláknový webový prohledávač založený na pythonu? Dejte nám vědět v komentářích.
Přečtěte si také: Jak vytvořit zaváděcí USB bez jakéhokoli softwaru v systému Windows 10